1. はじめに:クラスタリング手法をどう選ぶ?
以前、業務で混合データ(例えば性別職業などのカテゴリカル変数と、購買金額などの量的変数が混ざったデータ)を用いて、ユーザーのクラスタリング分類を行う機会がありました。
調べていくうちに、一般的に知られるK-Meansや階層型クラスタリングなどの数値データに使われる手法のほかに、カテゴリカルデータ(職業など)を考慮したクラスタリング手法(K-prototypes, Gower距離)があると知り、結局どのアプローチがいいの?と思ったため、実際に使用してみて比較することにしました。
疑問:カテゴリカル変数はどう扱えばいい?
疑問:結局、混合データのときはどのクラスタリング手法/アプローチが良いの?
2. 分析概要と目的
今回の分析では、健康や生活習慣に関する調査データを用いて、複数のクラスタリング手法を比較しました。
こちらは400人の健康/生活習慣の調査データで、数値情報(年齢、睡眠時間など)に加え、性別や職業、睡眠症状(不眠症/無呼吸症候群等)といったカテゴリカル変数も含まれている混合データだったためこちらを使うことにします。
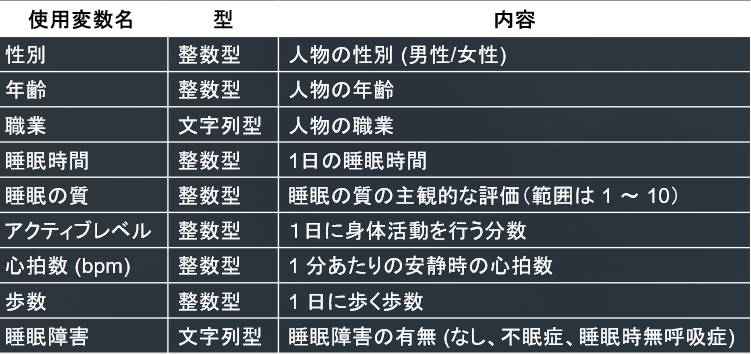
目的としては、このような混合データに対して、「どのクラスタリング手法がより適切にグループ分けできるのか」検討することです。
特に注目したいのは、「カテゴリカル変数をどのように扱うかによって、クラスタリングの結果解釈がどれほど変わるのか」ということです。K-meansのように数値データを中心に扱う手法に加え、K-prototypes や Gower距離などカテゴリカルデータに対応した手法を試してみます。
3. クラスタリング手法とアプローチ
こういった混合データの場合、考えられるアプローチは以下が挙げられます。
- 量的変数のみで分類:K-meansなどを用いて、数値データのみでクラスタリング分類→クロス集計でカテゴリカル変数についても特徴を見る
- 量的変数+エンコーディングしたカテゴリカル変数で分類:カテゴリ変数をOne-hotやOrdinalエンコーディングした後、K-means等でクラスタリング分類
- 混合データそのままで分類:K-prototypes、Gower距離+階層クラスタリング
- 潜在クラスモデル(LCA)
今回は1, 2, 3のアプローチを試します。(LCAは性質が異なるため別途扱うことにします)
具体的な手法は以下です。
- 1. K-means(量的変数のみ)
- 2. K-means(量的変数+カテゴリカル変数のエンコーディング)
- 3. K-Prototypes
- 4. Gower距離 + 階層型クラスタリング
💡K-Prototypesとは?
- K-meansとK-modesを組み合わせた手法で、数値変数とカテゴリ変数の両方を扱えるクラスタリング法
- 量的変数に対してはユークリッド距離
- カテゴリカル変数に対しては、シンプルマッチング非類似度(一致か不一致か)を用いる
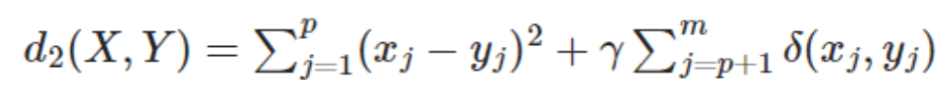
- 右辺の第1項は量的データから計算されるユークリッド距離、第2項が質的データから計算されるシンプルマッチング非類似度で、第2項の係数γが量的データと質的データの非類似度の重みを決めるパラメータ
- ※詳しく知りたい方は末尾参考サイトを参照されてください
💡Gower距離とは?
- Gower距離は、数値・カテゴリなど異なる型の変数間の類似度を統一的に計算できる指標
- 各変数タイプごとの距離を、正規化して合算することで、混合データにも対応できる
- 量的変数には、スケーリングされたマンハッタン距離
- カテゴリカル変数には、Dice距離を用います
- ※詳しく知りたい方は末尾参考サイトを参照されてください
4. 各手法の結果
今回、実装はPythonのKMeans(sklearn), KPrototypes(kmodes), gower等を用いて行いました。
また、分けるクラスタ群の数は、K-Means/K-Prototypesではinertia/costのエルボープロットを行い, gower距離+階層型クラスタリングではデンドログラムを見て決定しました。
1. K-means(量的変数のみ)
使用変数はこちら:
結果:
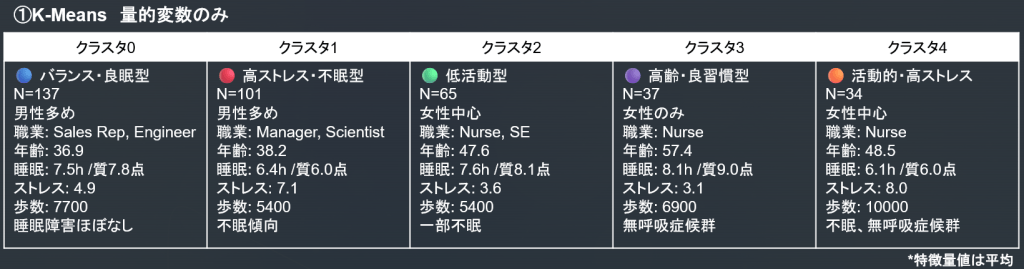
- かなりバランスよく分類されました。
- クラスタ1の男性/管理職サイエンティスト中心の不眠群や、クラスタ4の看護師の高活動高ストレス不眠群など、想像に難くない人々が浮き上がっています。
- 調査データの特性上、20%が看護師、19%が医者のようで、職業は看護師が多くなっています。
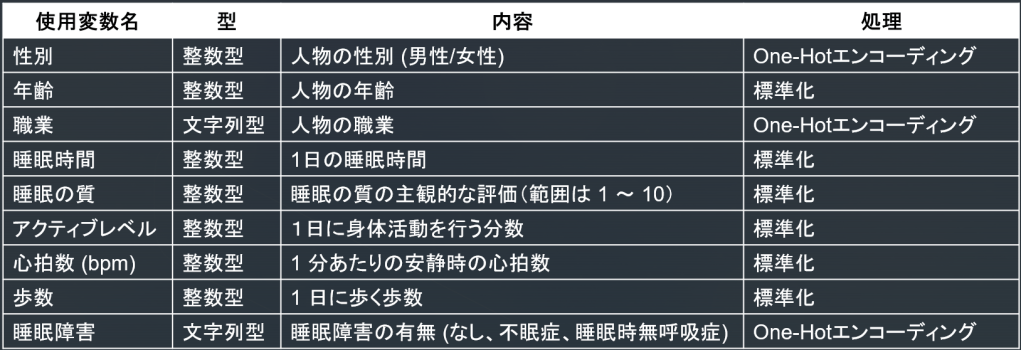
2. K-means(量的変数+カテゴリカル変数のエンコーディング)
使用変数はこちら:
結果:
- 職業のみ異なる、同じような特徴のクラスタが2つできてしまっています。
- 職業や性別により分類され、ほか数値がほとんど同じであったりと、やはりカテゴリカル変数の影響が強すぎる分類であることが見て取れます。

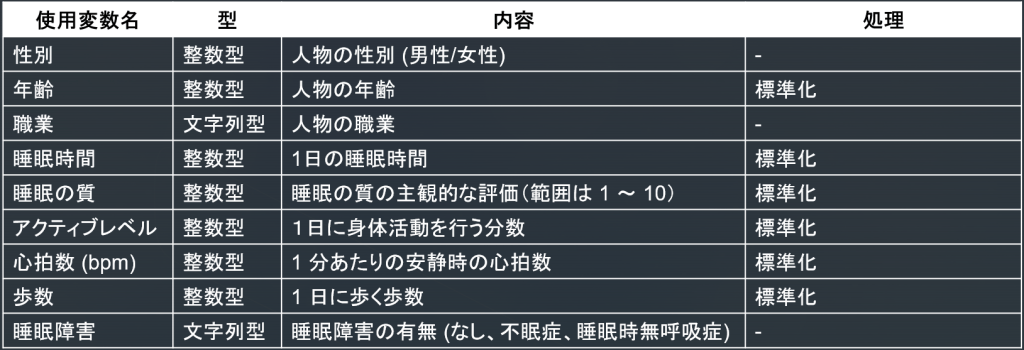
3. K-Prototypes
使用変数はこちら。混合データを、エンコーディングなしでそのまま使用します。
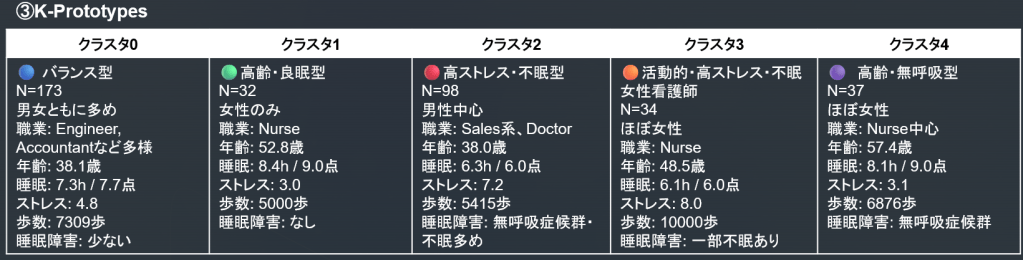
結果:
- バランスよく分類されました。
- クラスタ0, 1は良生活習慣で、クラスタ2, 3は高ストレスの不眠、クラスタ4は女性看護師の長い睡眠無呼吸症候群になっています。
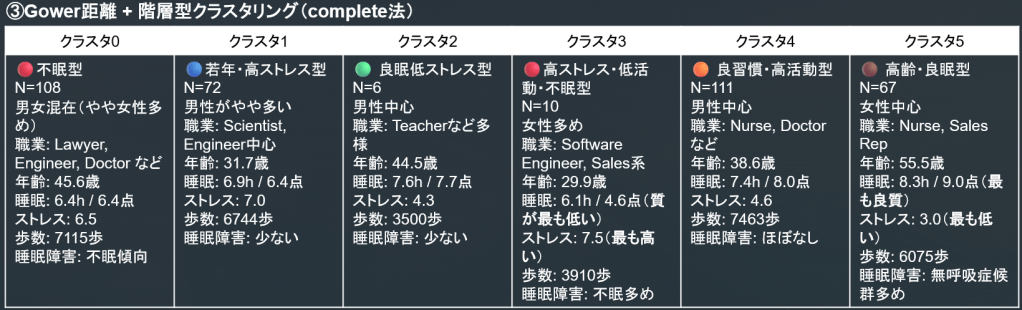
4. Gower距離 + 階層型クラスタリング
使用変数はこちら。こちらも混合データを使用。
結果:
- クラスタ群の人数に偏りができ、(群数を減らす/平均法等に変更しても)6人など一桁N数のクラスタができました。
- 特徴としてはバランスよく分けられているように見えます。
5. 手法比較まとめ
今回行った、クラスタリング4手法をまとめると以下になります。

結論として、①K-Means(量的変数のみ)、③K-Prototypesが良いと思いました。
①は、今回データには良くフィットしバランスよく分類できました。しかしカテゴリカル変数による差異が見たい場合、見られるかはデータとの相性次第になるのがデメリットかと思います。(実際業務でそのようなデメリットケースになることがありました)
③K-Prototypesは量的変数とカテゴリカル変数のバランスがとれた分類ができ、重みも調整できます。
④Gower距離については、階層型クラスタリングのWard法が使えないために大規模データに不向きというデメリットが大きいと感じます。
よって、①K-Means(量的変数のみ)→集計、③K-Prototypesを試し、分析データとのフィット/結果解釈を見ていくというアプローチが良いと思いました。
6. 参照サイト/文献
- Developer Interface — kprototypes 0.1.2 documentation
- 質的(カテゴリカルな)な特徴量があるときのクラスタリング手法とPythonでの実装について
- Pythonで学ぶk-プロトタイプ法:量的・質的データを同時にクラスタリングする方法 – セールスアナリティクス
- https://www.salesanalytics.co.jp/datascience/datascience067/
- 【技術解説】集合の類似度(Jaccard係数,Dice係数,Simpson係数) – ミエルカAI は、自然言語処理技術を中心とした
読んでくださりありがとうございます!

