1. 背景:潜在クラス分析をやってみたい
以前、業務でクラスタリングを行った際に、潜在クラス分析の存在を知りましたが、使用には至らなかったことがありました。
💡潜在クラス分析(Latent Class Analysis)とは
- 観測データの背後にある潜在的なクラス(グループ)を確率的に推定し、個々の観測値をクラスに分類する手法。
- 特長として、量的変数のみでクラスタリングするK-Meansや階層型クラスタリングと異なり、カテゴリカル変数でのクラスタリングや、量的変数とカテゴリカル変数の混合データでのクラス分類が可能。
- また、潜在クラス自身を説明変数とした目的変数の設定や、潜在クラスへの共変量を設定するといった、構造的に柔軟なモデリングができる。
- ※詳しく知りたい方は末尾の参考文献を参照されてください
そのため、量質混合データ1を用いて、潜在クラス分析を行ってみることにしました。
2. 使用データについて
Kaggleの[Online Gaming Anxiety Data]という、ゲームプレイヤー13, 464人へのアンケートデータを使用します。([元調査データ]・[元調査票(一部)])
◎データ概要
- 13,464人 (男性 12,699 人、女性 713 人、その他 52 人)へのアンケートデータ
- 18 歳から 63 歳 (平均20.9歳)
- 参加者は 109 か国に居住しており、そのほとんどは米国 (4,569 人)、ドイツ (1,413 人)、英国 (1,032 人)、カナダ (994 人)
- 質問に自由記述はなく、リッカート尺度のみ
データ選定にあたっては、ゲームプレイヤーのメンタル状況に興味があったことと、データ型が多様(ゲーム時間などの数値や、性別職業などのカテゴリや、個々質問への回答値など)なアンケートデータであることから選びました。
データ型が多様な量質混合データのため、潜在クラス分析を使用しがいがあるのではないかと思ったからです。
具体的な使用変数はこちらです。

3. 分析目的
今回は、「生活満足度」によるクラス分類(生活満足度スコアを潜在クラスの目的変数として、回帰構造を設定する)をしてみることにします。よって目的は以下とします。
- ゲームプレイヤーのメンタル状況において、生活満足度によるクラス分けをすると、どのような特徴が現れるのか調べる。
- 特に、生活満足度によって、ゲーム時間に傾向差が見られるか(クラスごとに特徴が異なって現れるか)調べる。
4. 仮説
仮説を考えます。
- 年齢や性別によって、生活満足度の傾向が異なる(年齢が高いほうが生活満足度が高い?)
- ゲーム時間が長いほど、生活満足度が高い?
- 不安スコアや社交不安スコアが低いほど、生活満足度が高い?
- 就業者は生活満足度が高く、学生と未就業者は生活満足度が低い傾向がある?
- ナルシズム度合いが高いほど、生活満足度が高い?
5. 手法とプロセス
今回はStepmixというPythonパッケージを用い、潜在クラスを推定し、それを説明変数として目的変数(生活満足度スコア)を予測する回帰構造を設定しました。
◎分析プロセス概要
- EDA:変数の分布の確認、全体傾向の把握(ヒストグラム、ペアプロット等)
- 前処理:対数変換、カテゴリ変数のエンコーディング、ダミー変数化
- モデリング:測定モデル、構造モデルの設定
- 特徴量エンジニアリング:VIFを確認し、特徴量選択
- モデル評価・選択:BICを用い、エルボープロットを用いてクラス数を決定
6. 分析結果
6.1 モデル選択過程
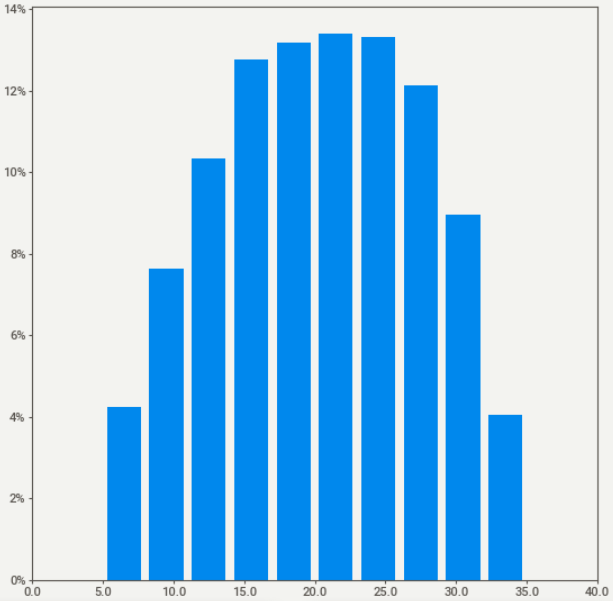
◎目的変数(生活満足度スコア)の分布
まず生活満足度スコアの分布をみると、釣り鐘型の切断正規分布に近い分布形でした。明らかな混合分布などは見られなかったため、このまま潜在クラスモデリングを行っていきます。
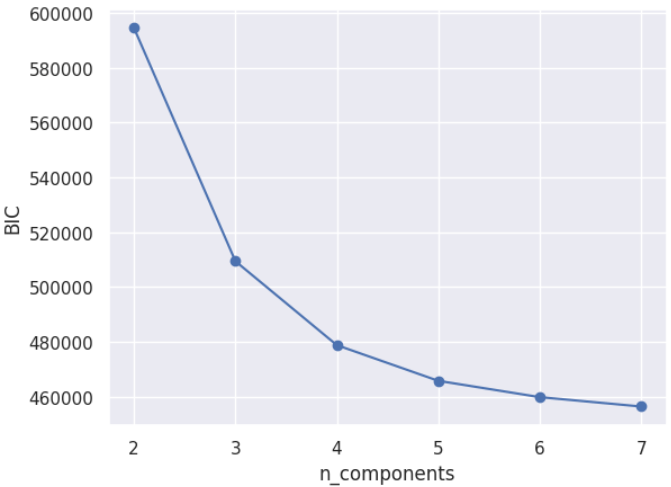
◎モデル選択
今回評価指標としては(参照論文をもとに)BICを用いました。分類するクラス数を2~8に変えてBIC値のエルボープロットを行い、クラス数4を最終モデルとしました。
6.2 最終モデルの結果概要
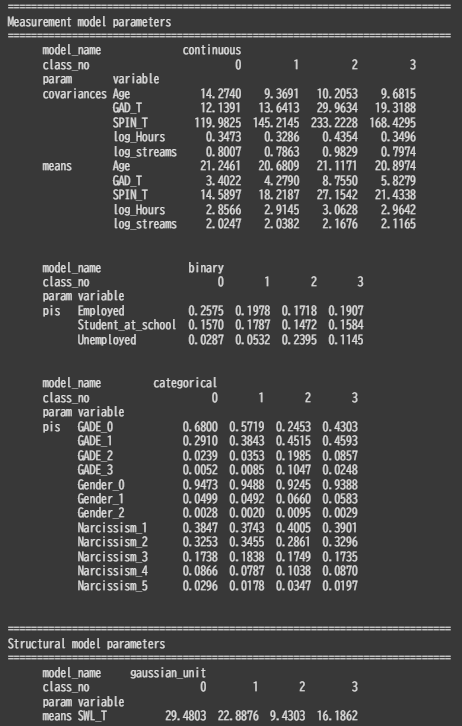
4クラスに分類を行ったところ、ゲーム時間/不安スコア/社交不安スコア/就業状況において、クラスごとに平均値差が見られました。
年齢や性別については、クラスごとに平均値に大差はなく、ナルシズム尺度においてもクラス所属確率に大差はみられませんでした。
参考:結果サマリーの出力(各変数について、それぞれの潜在クラスへの所属確率が算出される)
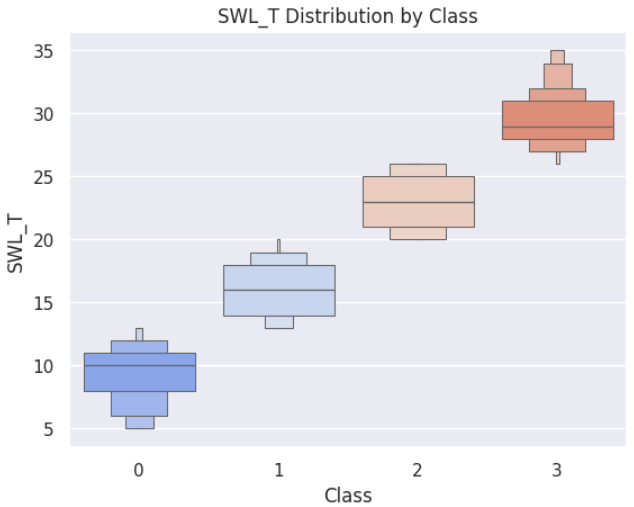
6.3 クラスごとの目的変数
分類クラスごとに、目的変数である生活満足度スコア(SWL_T)を見ると、クラス0が最も満足度が低く、クラス3が最も満足度が高く分類されていることがわかります。
6.4 変数ごとの深堀
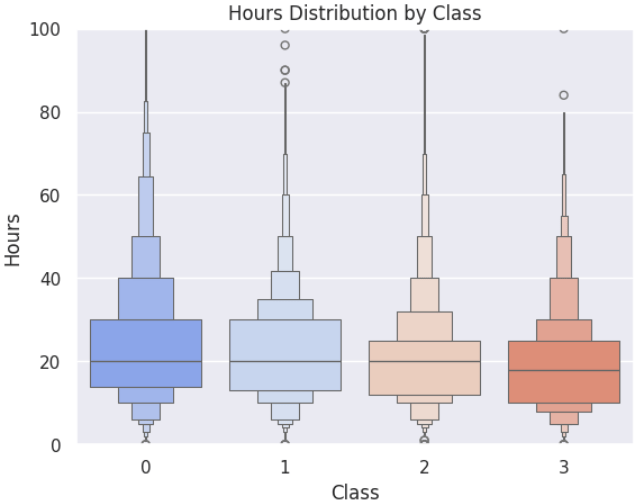
Hours(ゲーム時間)
分類クラスごとにゲーム時間の分布をみると、中央値はほぼ同じですが、生活満足度が高いクラスは、生活満足度低いクラス0と比較して、少ないゲーム時間に分布が集まっている傾向がありました。(生活満足度の最も高いクラス3の75%点は25時間, 生活満足度の最も低いクラス0は30時間)
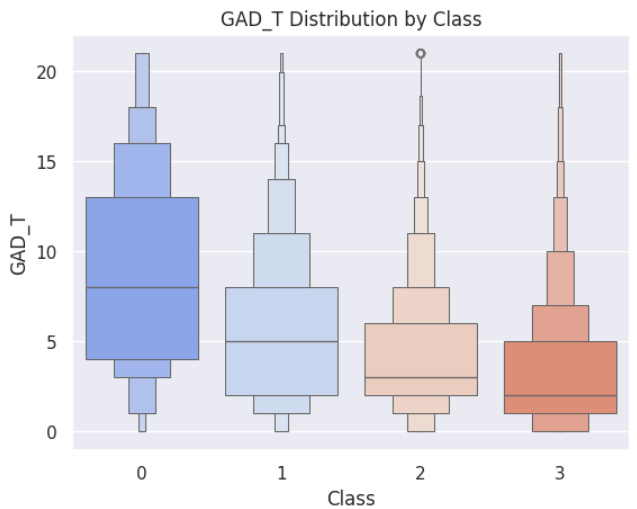
不安スコア
分類クラスごとに不安スコアの分布をみると、生活満足度が高いクラスほど、不安スコアが低く分布していました。(不安スコアの中央値は、生活満足度が高いほど低く、生活満足度が低いほど高い)
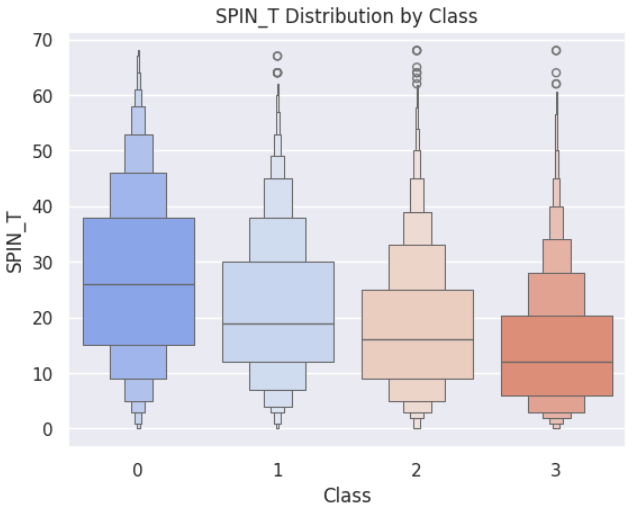
社交不安スコア
同様に分類クラスごとに社交不安スコアの分布をみると、生活満足度が高いクラスほど、社交不安スコアが低く分布していました。
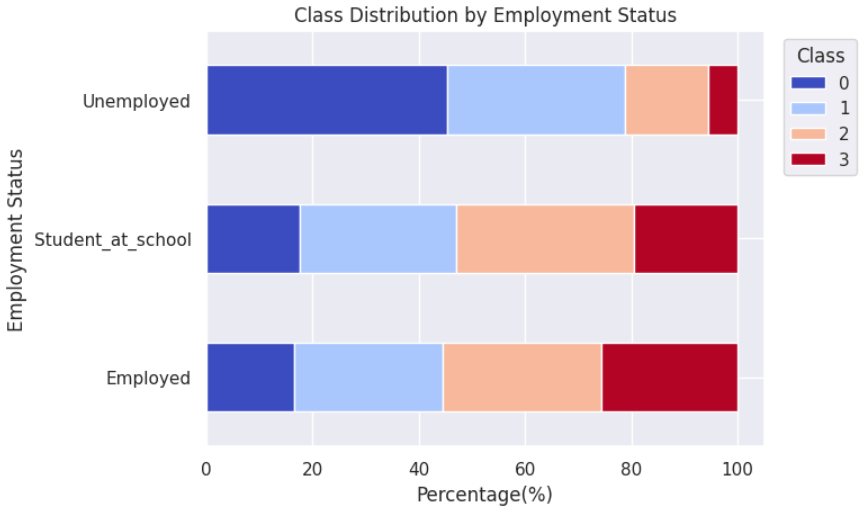
就業状況
また、就業状況によって、クラス分類に傾向差が見られました。
未就業者の約45%が最も生活満足度の低いクラスに分類され、就業者と学生との差が見られます。
6.5 結果まとめ
- 仮説1. 年齢や性別によって、生活満足度の傾向が異なる(年齢が高いほうが生活満足度が高い?)
- →年齢や性別には、クラスごとに平均値に大差はありませんでした。
- 仮説2.ゲーム時間が長いほうが、生活満足度が高い?
- →生活満足度の度合いによって、ゲーム時間の中央値に差はほぼなし。
- →生活満足度が最も高いクラスは、ほかクラスと比較して、ゲーム時間が短い時間に多く分布する傾向あり。
- 仮説3. 不安スコアや社交不安スコアが低いほうが、生活満足度が高い?
- →不安スコア/社交不安スコアは、生活満足度が高いほど低く、生活満足度が低いほど高い値に分布する傾向がありました。
- 仮説4. 就業者は生活満足度が高く、学生と未就業者は生活満足度が低い傾向がある?
- →未就業者の約45%が最も生活満足度の低いクラスに分類され、学生や就職者との分類割合と差が顕著に見られました。(就業者と、学生&未就業で傾向の差があるというよりも、就業者&学生と、未就業での傾向差が大きかった)
- →最も生活満足度が高いクラスに分類される割合が多いのは、就業者でした。
- 仮説5. ナルシズム度合いが高いほうが、生活満足度が高い?
- →ナルシズム指標における差は見られませんでした。
つまり、ゲーム時間の短さと生活満足度の高さの関連、不安/社交不安スコアの低さと生活満足度の高さの関連、就業者であることと生活満足度の高さの関連が見られました。
7. 考察
- ゲームプレイヤーの生活満足度には、ゲーム時間、不安スコア、社交不安スコア、就業状況が関連しており、年齢や性別/ナルシズム尺度は大きく関連していなかったです。(※年齢や性別については、不均衡データであるために傾向差が出ていないことも考えられます)
- ゲーム時間については、直接生活満足度へ影響するというより、「未就職である→ゲーム時間が長くなる→生活満足度が低い」のように、媒介的にゲーム時間の分布差が表れている可能性が高いのではないかと思います。(中央値はほぼ同じで75%値に差が見られたため)
8. 感想
◎やってみた結果としてのLCAの利点
LCAの利点の1つとして、K-Meansのように空間的な変数のみを扱う手法とは異なり、量的変数・カテゴリカル変数・アンケートの回答値変数を混合で分類モデルを作成できる点があります。
今回、想定では以下のようにクラスごとにペルソナ的な特徴をまとめられるのではないかと思っていました。
- クラス1:年齢20代、未就業と学生、ゲーム時間平均n時間、不安スコア平均n、ナルシズム度合い低め
- クラス2:年齢10代、学生、ゲーム時間平均n時間、不安スコア平均n、ナルシズム度合い低め
- クラス3:年齢30代、就業者、ゲーム時間平均n時間、不安スコア平均n、ナルシズム度合い高め
- …など
しかし、アンケート回答値による傾向差や、年齢性別による傾向差が出なかったため、今回データでは結果としてK-Meansなど量的変数でのクラスタリング+クロス集計でも同様の結果解釈が可能な分析になったと思います。
そのため、量的変数よりもアンケート質問が主もしくは全てで、とくに選択肢式/多肢選択式(MCQ)アンケートにおいて、LCAの真価が発揮されるだろうと思いました。回答選択肢それぞれにおける潜在クラスへの所属確率が出せるため、選択肢内容による直接の特徴解釈ができるからです。(実際論文や使用例で、選択肢式アンケートデータによく使用される理由を実感しました)
◎今回の分析の限界点
今回のクラスタリング分析では、特定の変数、ゲーム時間等と生活満足度の因果関係はわからないです。今回の結果からゲーム時間が職業状況の媒介になっているのでは?と思ったためこのデータについては構造分析をしてみたくなりました。
9. 参照ページ/文献
- stepmix – github
- stepmix – reference
- StepMix: A Python Package for Pseudo-Likelihood Estimation of Generalized Mixture Models with External Variables
- 潜在クラスモデル入門
- 潜在クラス分析を用いた計量社会学的アプローチ]
- マーケティングの統計モデル
- 数量的データ(数値)と質的データ(カテゴリ)を同時に含むデータのこと ↩︎
読んでくださりありがとうございます!

